
I recently looked at the GCP bill for the “Revenue Radar” agent I built (the one I documented in my “Beyond ‘Hello World’” deep dive), and the usage costs provided a significant and unexpected reality check.
The Python code was clean. The logic was sound. But the sheer volume of JSON I was shoving into Gemini’s context window for every single RAG retrieval was burning through credits like a startup burning through VC cash in 2021.
We talk a lot about AI “Hallucinations” and grounding strategies (I covered this in “The Mirage of Omniscience”), but we don’t talk enough about Tokenflation. JSON is verbose. It loves its curly braces, its quotes, and repeating keys over and over again. It is the data equivalent of that friend who packs two large suitcases for an overnight trip.
Enter TOON (Token Oriented Object Notation).
I’ve been experimenting with this in my local Digital Garden stack, and honestly? It’s a fascinating, messy, high-risk, high-reward architectural choice. Let’s break down the plumbing.
💸 The “Current Reality”: Structure Costs Money
Here is the brutal truth of Enterprise RAG: Syntax isn’t free.
When you pull 50 Case records from Salesforce to give an agent context on a customer’s history, you aren’t just paying for the data (the actual complaint text). You are paying for the structure wrapping it.
Standard JSON is “self-describing,” which is polite engineer-speak for “repetitive.” If you send a list of 100 objects, you are sending the key names (e.g., "customer_email", "case_status", "created_date") 100 times. That is wasted context window. That is the JSON Tax.
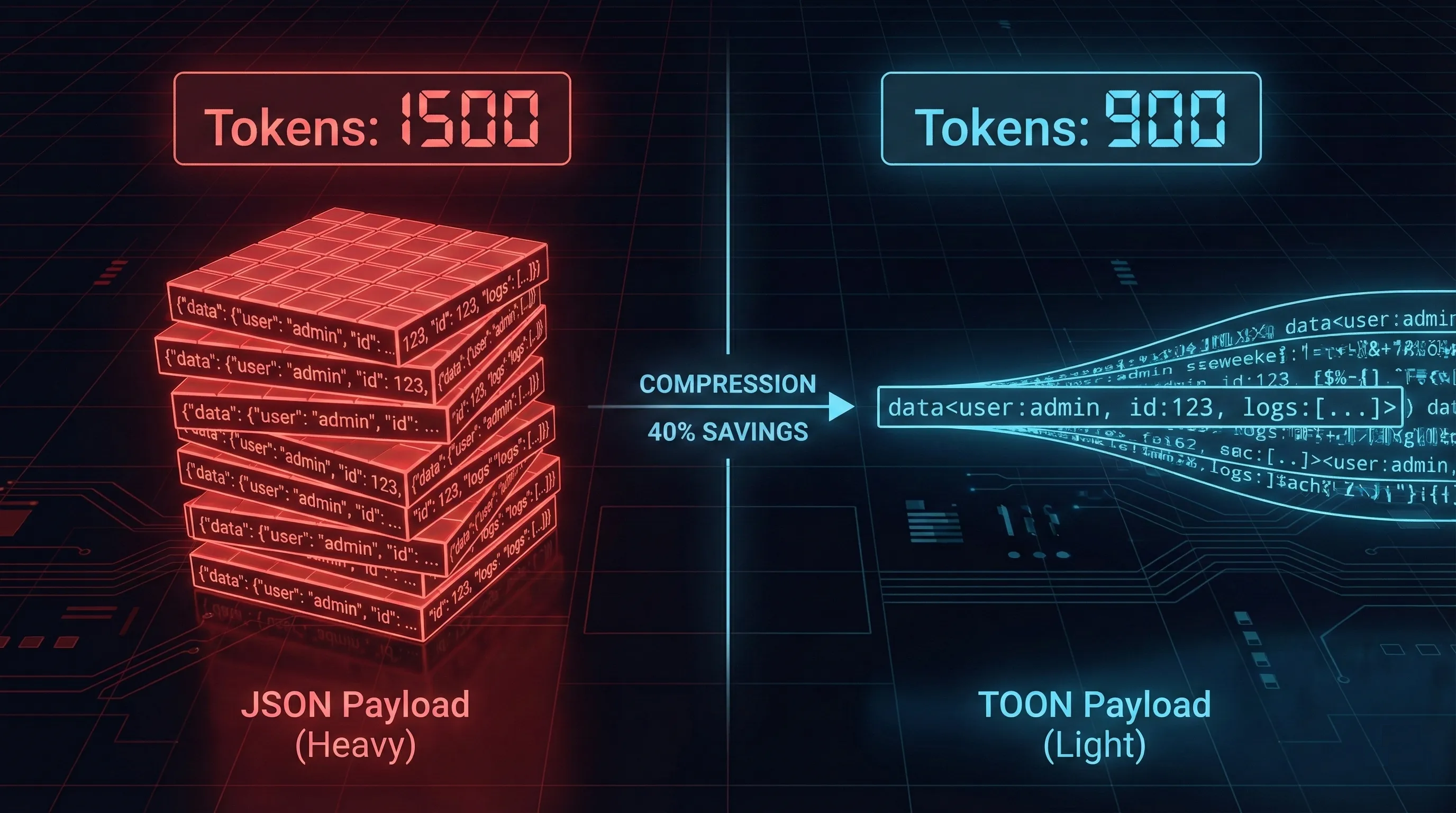
🏗️ What is TOON? (The “Zip File” Analogy)
TOON is a minimalist data serialization format designed specifically for LLMs. It strips away the “syntactic sugar” of JSON to represent structured data using indentation and significant whitespace. It functions like a hybrid of YAML and CSV header optimization.
Think of it this way:
JSON is the uncompressed folder. Easy for humans to read, but bulky to transport.
TOON is the
.zipfile. Great for moving data cheaply across the wire, but you have to unpack it before you can use it.
The Plumbing: TOON uses a “Head-First” schema declaration. You tell the LLM the structure once at the top, and then you just stream the values.
Compare the difference:
The JSON Way (Paying the Tax):
JSON
[
{"id": "C-001", "role": "admin", "status": "active", "region": "NA"},
{"id": "C-002", "role": "user", "status": "pending", "region": "EMEA"},
{"id": "C-003", "role": "user", "status": "active", "region": "APAC"}
]
The TOON Way (The Diet Plan):
Plaintext
users[3]{id, role, status, region}:
C-001, admin, active, NA
C-002, user, pending, EMEA
C-003, user, active, APAC
By stripping the braces and repetitive keys, TOON can yield a 30-50% reduction in token count for high-density lists. In the world of $0 cost architectures (my obsession since writing “Architecting Freedom”), that is massive.
🏛️ The Hybrid Enterprise Context (Salesforce + The “Real World”)
Here is where my “Real Talk” persona kicks in. If you are working in an Enterprise ecosystem like Salesforce, you hit a wall immediately.
Agentforce, Data Cloud, and standard Salesforce APIs speak JSON. Their entire “Structured Outputs” architecture is built on standard JSON Schema. They do not natively support TOON. You cannot store TOON in a Salesforce record and expect to index it.
So, if you want these savings, you have to build the plumbing yourself. You have to treat TOON purely as a transport layer.
The Augmentation Pattern: To make this work with my “Revenue Radar” agent, I had to introduce an external compute layer (I used a lightweight Python container on Google Cloud Run):
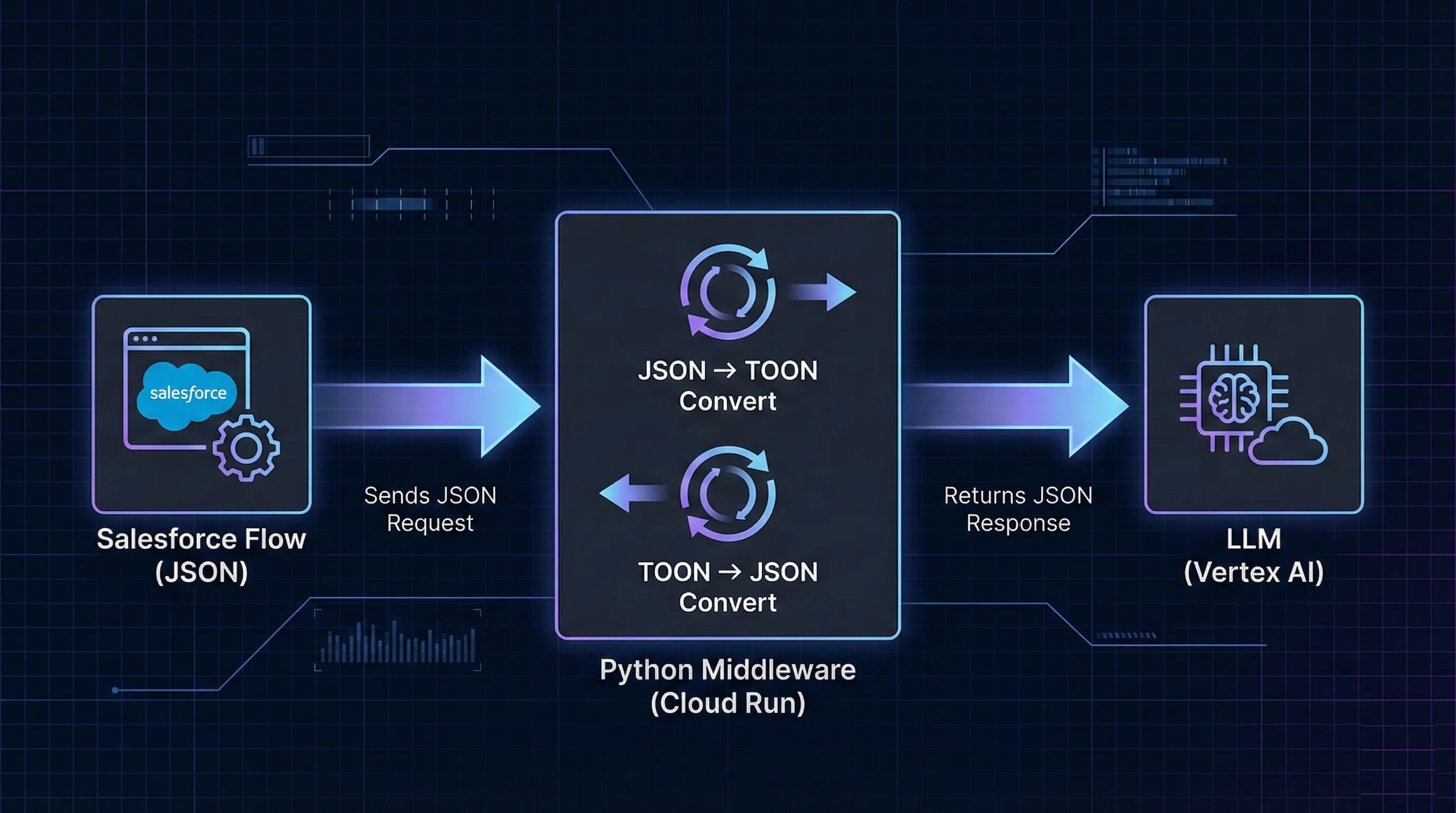
Salesforce Flow triggers a webhook (sending standard JSON out).
Middleware (Python) catches the payload and converts JSON -> TOON.
LLM Inference happens (saving tokens on the input).
Middleware converts the response TOON -> JSON.
Salesforce receives JSON and updates the record.
Is it over-engineering? Perhaps. But for a batch-processing agent analyzing 10k logs daily, the ROI is mathematically undeniable.
⚠️ The Reality Check (Where It Breaks)
I never paint a perfect picture. Every bleeding-edge tech has a “Kill Chain.” Here are the Gotchas with TOON right now:
“Hallucinated Formatting”: Current LLMs are trained primarily on the internet, which is mostly JSON and HTML. They are “fluent” in JSON, but they have to “translate” TOON. Occasionally, the model gets confused mid-stream and reverts to Markdown or JSON, utterly breaking your parser on the return trip. You need robust fallback logic.
The IQ vs. Token Trade-off: Marketing claims “lossless compression,” but benchmarks show that while simple lists map well, deeply nested structures in TOON often confuse LLMs, leading to a 10-20% drop in reasoning accuracy. You are trading IQ for tokens. If accuracy is paramount, swallow the cost and stick to JSON.
Security & Injection Risks: JSON parsers are strict; they fail hard on a missing comma. TOON parsers are often “fuzzy,” relying on whitespace interpretation. A malicious Prompt Injection could manipulate the whitespace structure to hide data or alter the schema definition, leading to downstream logic errors that a strict JSON parser would have caught.
🔮 The Future State
Right now, we are in the “Wild West” of token optimization. Libraries are fragmented, and specs are competing.
However, the “North Star” isn’t TOON. It isn’t JSON. Eventually, we may (probably will) move past human-readable text entirely to vector-to-vector communication. We won’t need these intermediate formats for machine-to-machine agents. But until that day arrives, TOON is the best hack we have to keep our API bills from exploding.
💬 Let’s Argue
I’m genuinely torn on this approach. On one hand, the efficiency-obsessed engineer in me loves TOON. On the other hand, the pragmatic architect in me hates introducing a custom middleware layer just to save $50 a month. It feels dangerously close to “Resume Driven Development.”
Is the “Complexity Tax” of maintaining custom parsers and middleware worth the token savings for your specific use case?
Do you trust current LLMs to reliably parse a non-native format in production, or is the risk of “hallucinated formatting” still too high?
Drop a comment below. I learn as much from the debate as I do from the documentation.
🌱 Want more experiments? This is just one plant in my digital garden. I’m constantly breaking things, hitting limits, and documenting the fixes over at my personal site.
If you like deep dives into the “Real World” of Enterprise AI (minus the marketing fluff), go check it out:👉 Pavan’s Digital Garden